Your analysts need freedom to experiment with data. But without the right guardrails, that freedom can spiral into runaway storage costs, governance gaps, and security risks. Snowflake Time Travel is a powerful feature for recovering and versioning data, yet it often becomes an unexpected cost driver in sandbox environments where high-churn experiments multiply storage overhead.
Here is the challenge: reducing Time Travel retention from 90 to 7 days can yield 15-25% storage savings. But cutting retention too aggressively in the wrong places can leave you exposed when disaster strikes. The key lies in building a secure data sandbox architecture that balances cost optimization with robust governance.
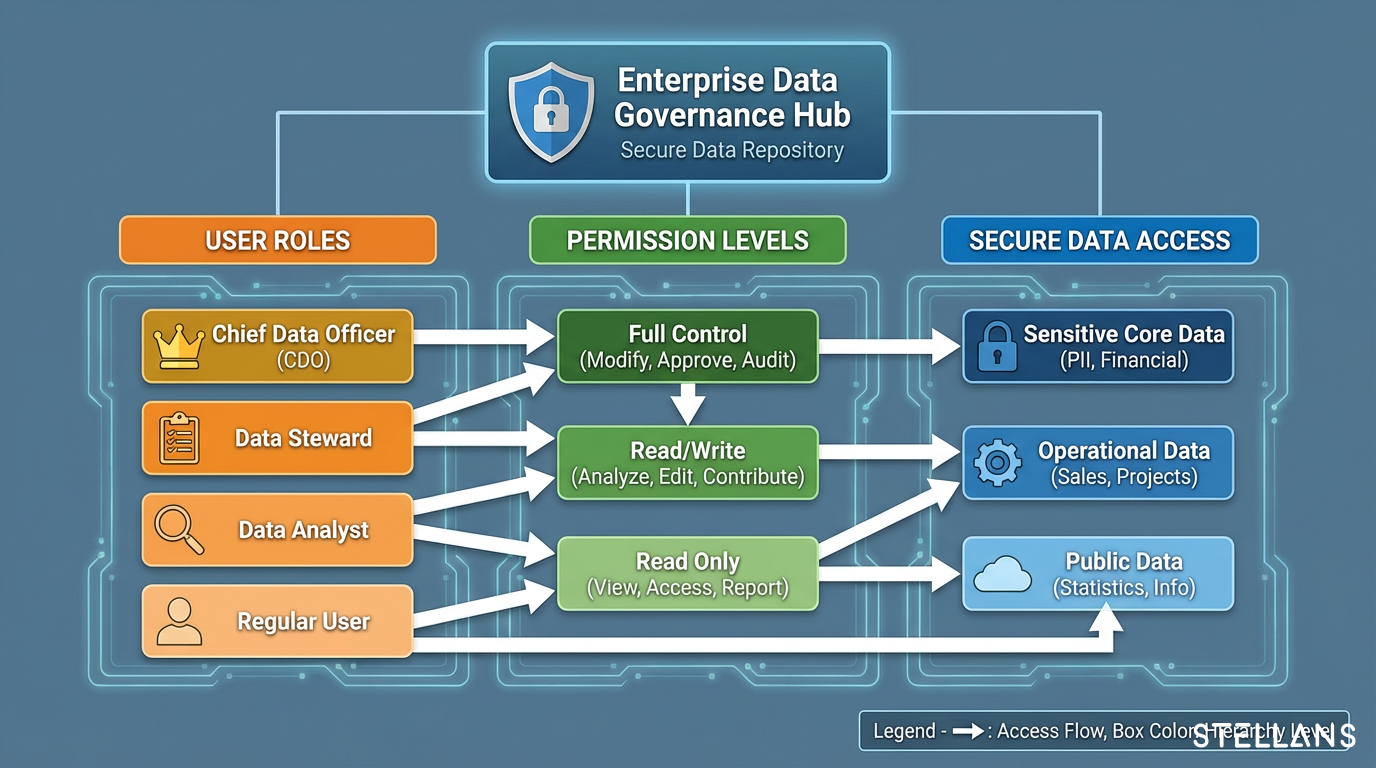
In this guide, we walk through how to configure Snowflake retention policies within isolated sandbox environments. You will learn how to leverage transient tables, implement Role-Based Access Control (RBAC), use masked or synthetic data, and safely promote validated work to production. This is the approach we use with our clients to help teams report 40%+ cost reductions while maintaining secure analyst access.





























