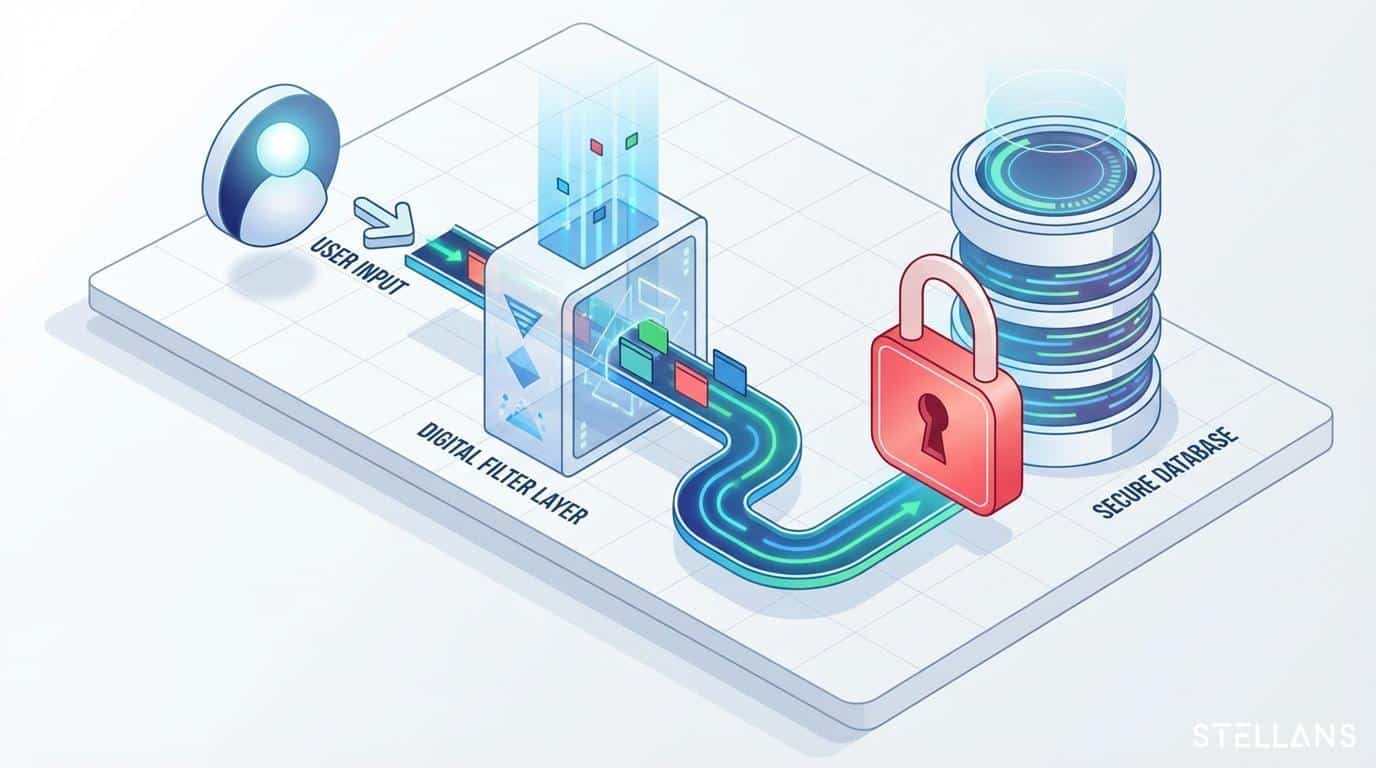
Is my private data safe when using Generative AI for analytics?
Yes, provided the correct architecture is used. At Stellans, we utilize a “schema-only” approach. We send the structure of your database (table names, column types) to the LLM to generate SQL code, but the actual rows of data (customer names, financial figures) remain in your secure environment and are never shared with the model provider.
How do we prevent the LLM from hallucinating incorrect numbers?
We mitigate hallucinations by asking the LLM to write code (SQL), not to perform calculations. The LLM acts as a translator, converting your English question into a SQL query. The actual mathematical calculation is executed by your deterministic database engine (like Snowflake or PostgreSQL), which ensures the numbers are mathematically accurate.
Can GenAI replace my data analysts?
No, it empowers them. Generative AI handles the repetitive, ad-hoc questions (“What were sales yesterday?”) that consume an analyst’s time. This frees your data team to focus on high-value tasks like predictive modeling, infrastructure optimization, and complex strategic analysis that requires deep human context.
What is a Semantic Layer and why do I need one?
A semantic layer is a set of business definitions that maps complex data structures to business terms. For example, it tells the AI that “Gross Profit” equals “Total Revenue” minus “COGS”. Without this layer, the AI effectively guesses at meanings based on column names, which often leads to inaccurate queries.