Before debating pipeline architecture, we need to clarify what these acronyms actually mean in practice. The differences dictate how your organization approaches data transformation strategies.
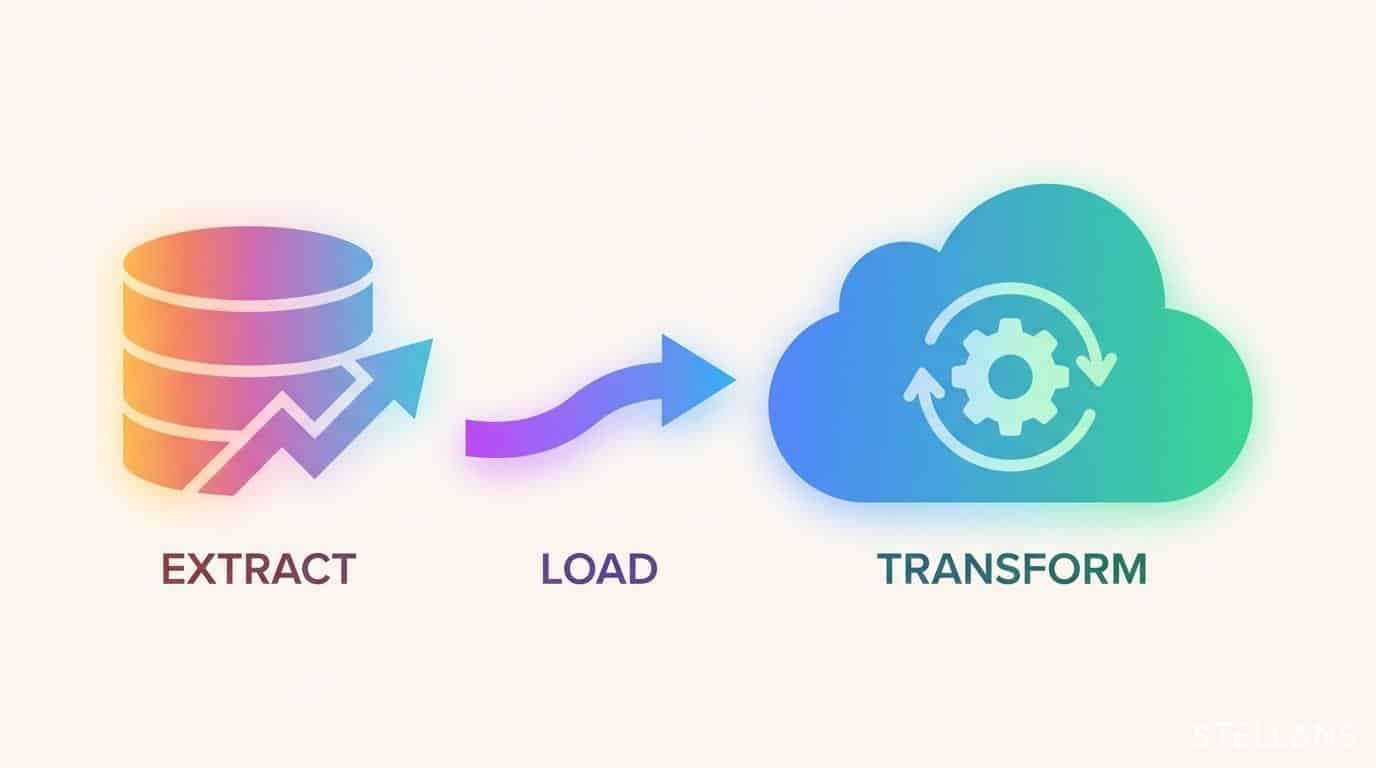
What is ETL (Extract, Transform, Load)?
ETL stands for Extract, Transform, and Load. In this sequence, data is extracted from the source, transformed on a dedicated server, and finally loaded into the target data warehouse.
Historically, this sequence evolved out of pure necessity. Legacy on-premise warehouses were expensive: computing power and storage were highly constrained. To save warehouse server costs, data engineers pre-aggregated and transformed raw data on separate ETL servers before insertion. This kept the warehouse efficient, but it created brittle pipelines. Streamlined modern operations prevent the heavy maintenance overhead and entirely new deployments previously required by any schema update.
What is ELT (Extract, Load, Transform)?
ELT stands for Extract, Load, and Transform. We extract data from the source, dump the raw data first into the target destination, and apply elastic warehouse compute later to execute transformations.
Cloud computing reinvented the sequence. Since modern warehouses offer near-limitless storage capacity, we can confidently store rich historical datasets directly, without pre-aggregating data, to save space. We load raw data directly, preserving a historical source of truth. The transformation happens natively within the warehouse using pure SQL. This accelerates data availability while reducing tool dependency.