Recommendation systems
are a crucial component of any evolving B2C business today. They are integrated into many familiar products, from internet search engines and video services to the display of relevant advertisements. Each year, more applications utilizing recommendation systems emerge.
Let’s start with the basics. How are recommendation systems structured, and what types are there?
In the classic approach,
personalized recommendation systems can be divided into three major groups:
Content-Based Recommendation Systems
Recommend items to users that are similar to those they have already purchased or rated positively. Similarity is assessed based on the attributes of the items themselves.
Collaborative Filtering Systems
Build recommendations based on the rating history of both the user and other users.
Hybrid Recommendation Systems
Combine both approaches to increase accuracy and offer more flexible customization for different customer groups. However, this approach is more complex to implement and maintain.
Collaborative Filtering Systems
Now, let’s take a closer look under the hood. We’ll start with collaborative filtering systems. This approach involves finding similar users or items and using their preferences for recommendations. Let’s consider a classic example: an online movie theater. Suppose there are two users, James and Hugh. James rated “Equilibrium” five stars, and he also gave five stars to “Lock, Stock and Two Smoking Barrels” and “Fight Club.” Hugh has the same ratings for these films, so we assume their tastes are similar. However, Hugh also rated “Kill Bill” five stars. Based on this, we recommend “Kill Bill” to James. In a nutshell, this is collaborative filtering.
The approach is based on two assumptions:
- Two users with similar tastes will continue to share these tastes.
- Two items with similar fan bases will remain popular among users who are similar to those fans
Next, we delve
into the details of implementation. How do we find similar customers? First, we need to know what existing customers liked. Feedback in this context can vary. Ideally, we use explicit feedback—user ratings. However, feedback can also be implicit. Let’s consider the example of an Instagram feed. Yes, Instagram has examples of explicit feedback, like likes and reposts. But we don’t always like posts even if we enjoy them. Here, implicit feedback comes into play. If a user quickly scrolls past a video, it’s probably not interesting. If they watch it to the end, it’s likely more interesting. And if they watch it multiple times? These are all examples of implicit feedback, each with varying degrees of strength. These signals can be used alongside explicit feedback.
In the case of a movie theater, we also have explicit feedback—user ratings, and implicit feedback—such as the duration of the movie watched (whether they watched it to the end or not). Let’s put this into practice.
Great, we have user feedback. Let’s start recommending!
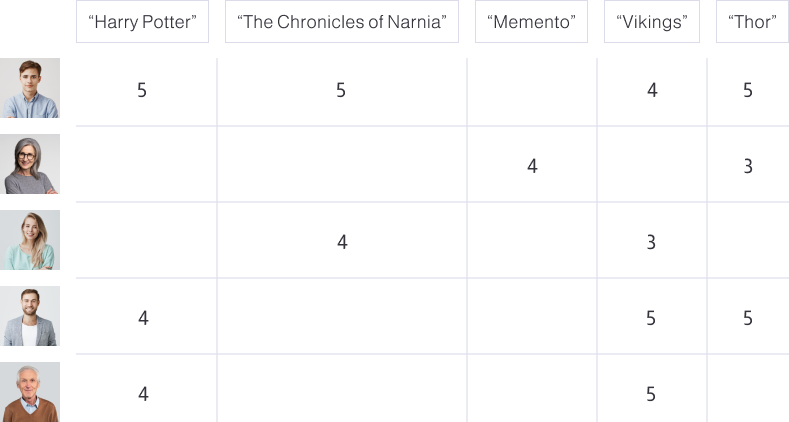
To recommend
something to a user, the first thing we need to do is find similar users (we’ll use a rating matrix for this example). There are several ways to do this, each with its drawbacks. However, let’s focus on cosine similarity. In this toy example, let’s try to recommend something to a user named Viking. The most similar ratings are from the users in the 1st and 4th rows. We will take their average ratings for the movies that Viking hasn’t seen yet. In this case, it will be 4 for “The Chronicles of Narnia” and 5 for “Thor”. These are the recommendations.
However, a more commonly used approach is based on matrix factorization (SVD). While pure SVD may not work perfectly for this task, its modifications (such as Funk SVD, one of the earliest) can.
This method allows us to represent the rating matrix as two smaller matrices. One essentially represents embeddings reflecting user taste preferences, and the other represents embeddings reflecting movie characteristics (just as shown on the chart below).
What Does This Give Us?
For most approaches, we cannot say that two movies are similar if no one has watched them both. Typically, many methods are based on having users who have interacted with both items A and B, allowing us to determine their similarity through this interaction. Collaborative filtering in the form of SVD allows us to do this even if no user has watched both movies. Additionally, by having a movie vector, we can recommend it to a much broader audience and recommend significantly less popular movies. Moreover, we obtain a vector representation of movies, which is very convenient to work with, making it easy to quickly find similar films.
if we want to predict whether
a user will like a movie they haven’t seen yet, we can multiply their embedding by the movie’s embedding to get an approximate rating.
This approach has its drawbacks. For instance, it doesn’t take into account specific information about the user or the recommended item. This method also has a pronounced cold start problem. What do we recommend to a new user if their vector is unknown? Additionally, if your service has thousands or even hundreds of thousands of items, and most of them have feedback from only a few users, the embeddings can be very unstable and poorly represent the item’s properties. However, there are solutions to all these problems, which we will not cover here.
Content-Based
Recommendation Systems
Content-based recommendation systems use machine learning methods to solve classification or regression tasks. They take user features and item features as input, and the output is the relevance score of a given item to a given user. These models are trained not on the interactions of all users and all items, as in collaborative filtering methods, but rather on individual instances.
Content-based recommendations are often used for items with unstructured descriptions, such as movies, books, and articles. Features can include text descriptions, reviews, cast members, and more. However, there’s nothing to prevent the use of standard numerical or categorical features as well.
There are also simplified variants where the user’s data vector is not considered (though these are better categorized as non-personalized recommendations on steroids). For example, let’s look at book recommendations. Typically, each book has a content description and a genre. We can use neural networks based on the Sentence Transformers library, which are specifically trained to represent text in a vector format suitable for search. Using these, we can also obtain a vector representation for the book’s genre. By using cosine similarity, we can find the most similar books and recommend them to the user. This is a fairly simple approach, but it effectively finds similar works and recommends them to the user.
One of the advantages is that recommendations can be calculated in advance for each item and shown to the user. However, there remains one problem—they are still not personalized.
Hybrid Systems
Hybrid models combine the strengths of both approaches, offering high-quality recommendations in a reasonable time.The most popular hybrid approach today features a two-tier architecture. In this setup, a collaborative filtering model selects a small number (100-1000) of candidates from all possible items, which are then ranked by a much more powerful content-based model. Sometimes, there can be multiple stages of candidate selection, with increasingly complex models used at each new level. An example of such a solution is illustrated below.
Candidates at the first level are selected by a collaborative filtering model. These candidates are then ranked by a content-based model. The content-based model receives user features, item features, and interaction features as input.
User features can include data about the device, attribution, user age, and preference vectors. In more complex models, it might also include the history of interactions with previous content. For the item, features might include (if the item is a movie): genre, release year, country, actors, director, age restrictions, etc. It’s also beneficial to add business metrics: the percentage of visits to the movie’s page, the number of views, additions to favorites, distribution by viewing methods, devices, countries, and so on.
Interaction features can include scores from the candidate selection stage (essentially the predictions from the collaborative filtering) and aggregated statistics from all previous interactions of the user with movies featuring the same actors, directors, and screenwriters, as well as movies with similar plots.
As mentioned earlier, the second-level model can be a simple binary classification model predicting the likelihood that the given content is relevant to the given user. However, there are more elegant solutions, such as using LambdaMART, which enables the model to learn how to rank examples by relevance within the context of a single user.
In implementing such a system, there are several considerations. Some features are best precomputed and kept up-to-date (e.g., user and content features). However, interaction features may need to be calculated on the fly.
Non-Personalized Recommendations
It’s important to note that, in addition to personalized recommendations, there are also non-personalized recommendations. We won’t delve into them in detail, but my favorite example can be seen in online food ordering. When you add an item to your cart, you might see several items labeled “often bought with this item.” Such recommendations are usually based on associative rules. Associative rules are frequently used in Market Basket Analysis. For instance, if a customer adds milk to their cart, bread is also present in 80% of cases. Thus, if we see milk in the cart while bread is still not, it’s a good time to remind the customer about bread.
In Conclusion
Let’s talk about the effectiveness of recommendation systems. It is challenging to quantify how much advanced recommendation systems improve business metrics compared to products without recommendations. This is partly because recommendation systems improve gradually, and typically, through A/B testing, we can compare the old and new versions of the recommendation system, or its absence with the initial versions within the company. Additionally, numbers vary significantly depending on the business.
For example, in the case of a large news site, it was shown that news selected for the user through simple collaborative filtering received 30% more views than those selected based on tags of previously viewed news, and seven times more than the recommendation of popular news! In the case of YouTube, it is known that certain updates to the recommendation service increased CTR by 35% [1] , while for eBay, the implementation of a new recommendation system showed an increase in revenue by approximately 6%. [2]
According to publicly available data from 2022, about half of all installs on Google Play come from recommendations, while more than 60% of all videos viewed on YouTube also originate from recommendations. All of this especially underscores the importance of recommendations for a range of products. Users have become accustomed to good recommendations on platforms like YouTube, Instagram, and Amazon, which gradually makes recommendations a necessity in many other smaller products.
Here at Stellans, we will create the optimal recommendation system tailored to your business, help integrate it into your product, and evaluate its effectiveness.