Growth teams at SaaS companies face a common challenge: too many leads, not enough time, and no clear way to prioritize. Without data-driven scoring, sales reps waste hours chasing prospects who never convert while high-intent buyers slip through the cracks.
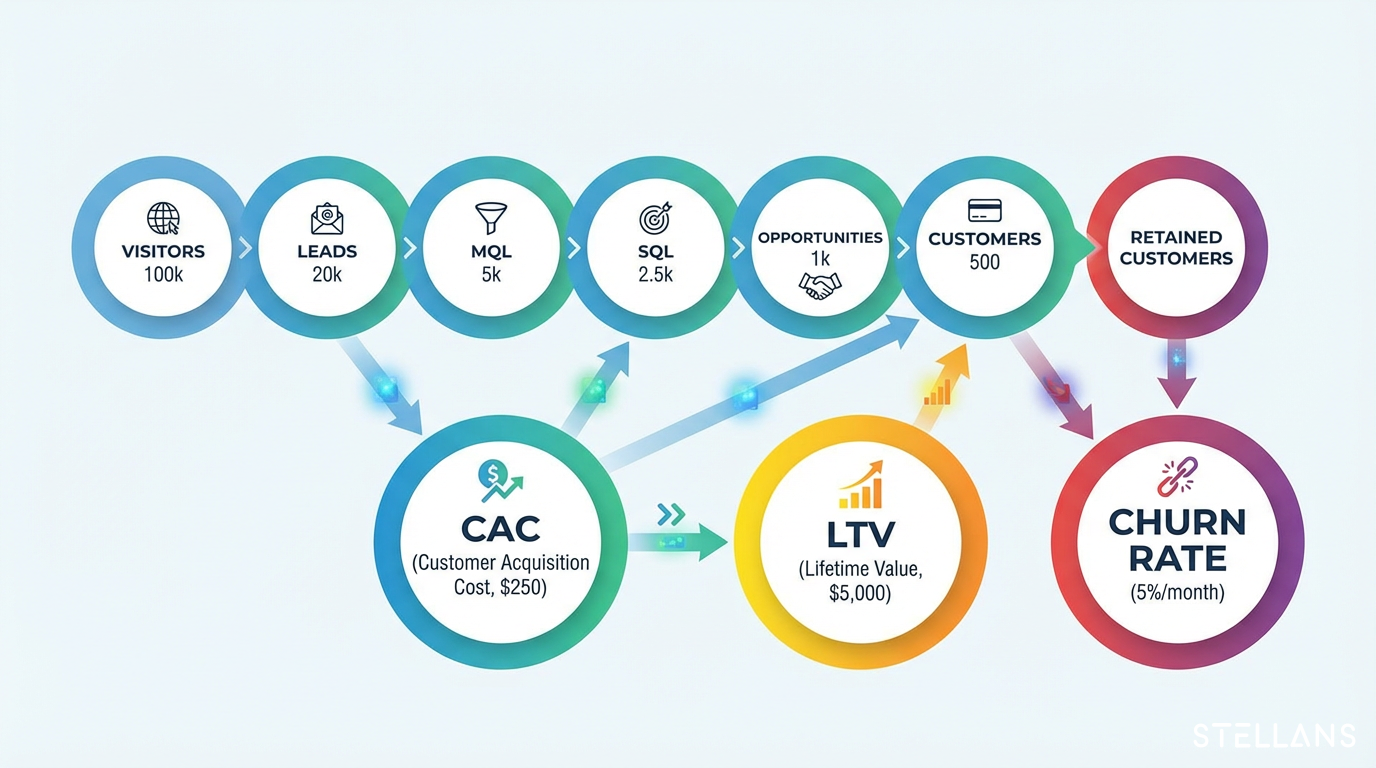
The solution lies in understanding your funnel metrics and building predictive lead-scoring models that surface conversion probability for every prospect. Customer Acquisition Cost (CAC), Customer Lifetime Value (LTV), and churn rate form the foundation of this approach. These metrics do more than measure business health. They inform the features you build into your scoring models.
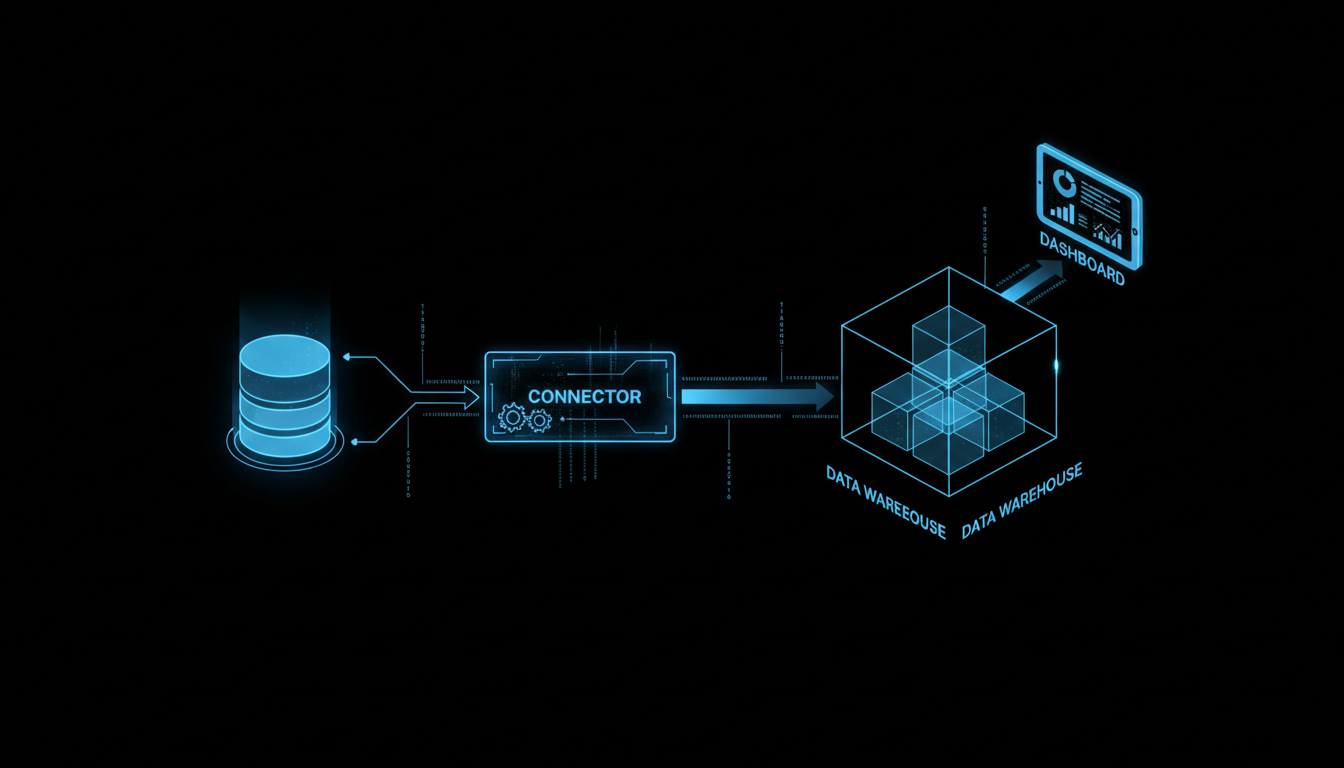
In this guide, we walk through both the theory and the hands-on implementation. You will learn how CAC, LTV, and churn definitions translate into actionable model features. Then, we cover the complete pipeline: SQL data extraction, dbt feature engineering, Python model training with scikit-learn, and productionizing scores back to your data warehouse.
This knowledge comes from our work with marketing analytics teams, growth strategists, and technical specialists who need their data stack to drive real results.