Machine learning (ML) has graduated from the realm of academic R&D labs and hypothetical discussions to become a fundamental baseline for competitive business strategy. The focus is now on how effectively you can transition from “AI interest” to actual machine learning implementation, rather than if you should leverage artificial intelligence.
Achieving specific, value-generating ML requires navigating complexity. A staggering number of AI initiatives (some sources cite up to 85%) fail to move past the Proof of Concept (PoC) stage. They linger in “pilot purgatory” usually because the strategy connecting the code to the business outcomes is missing, not because the algorithms are flawed.
At Stellans, we believe success comes from having the smartest strategy rather than just the smartest algorithm. We work with you to turn the hype into a well-oiled machine that drives decision-making and efficiency. Whether you are a CTO looking to optimize supply chains or a CDO aiming to personalize customer experiences, the principles of deployment remain the same.
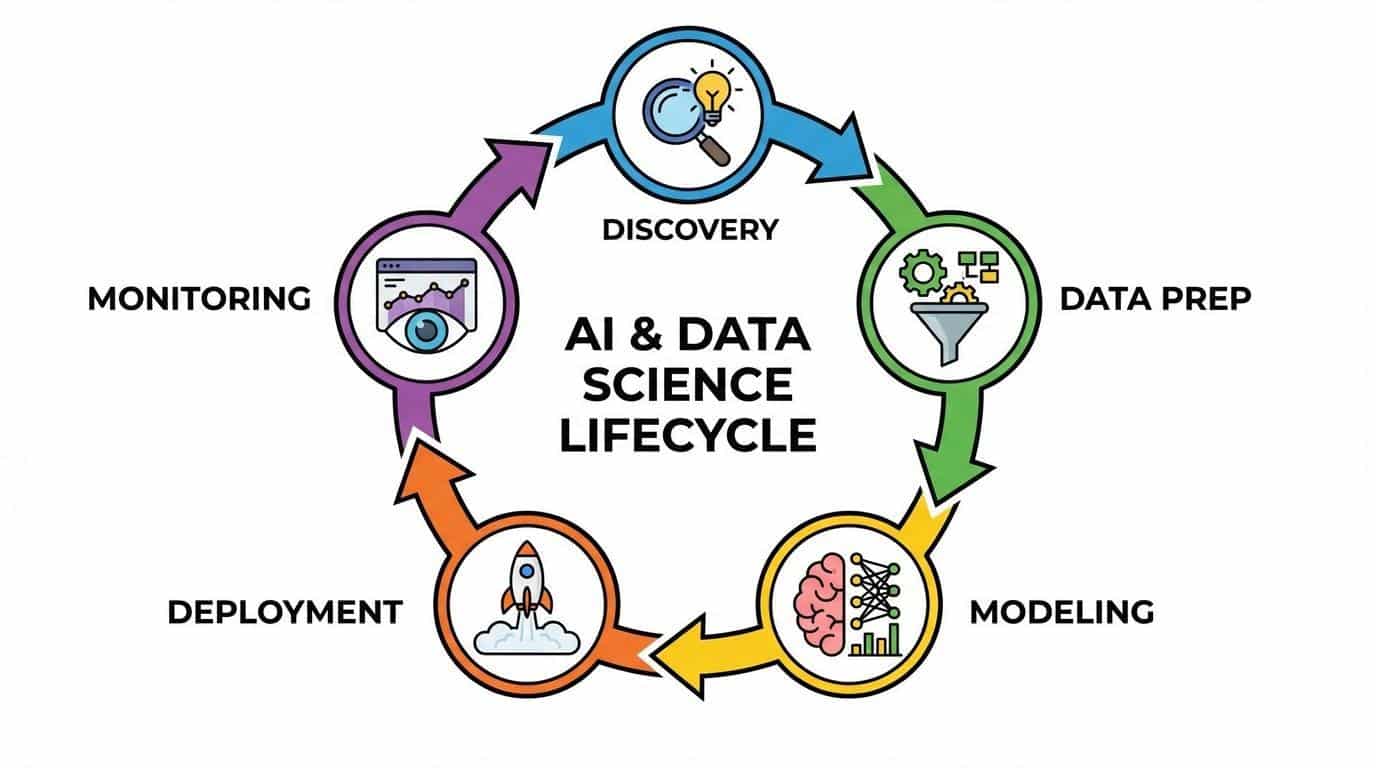
This guide acts as your strategic roadmap. We will walk you through how to implement machine learning by treating it as a disciplined product development cycle rather than a science experiment.